And you can ingest data in real time in batches or using a lambda architecture. Just as a traditional pipeline carries water or oil from one place to another a data ingestion pipeline is a solution that carries data from point A to point B.
 Continuous Data Ingestion Pipeline For The Enterprise
Continuous Data Ingestion Pipeline For The Enterprise
It is tuned to receive and process millions of data per seconds.
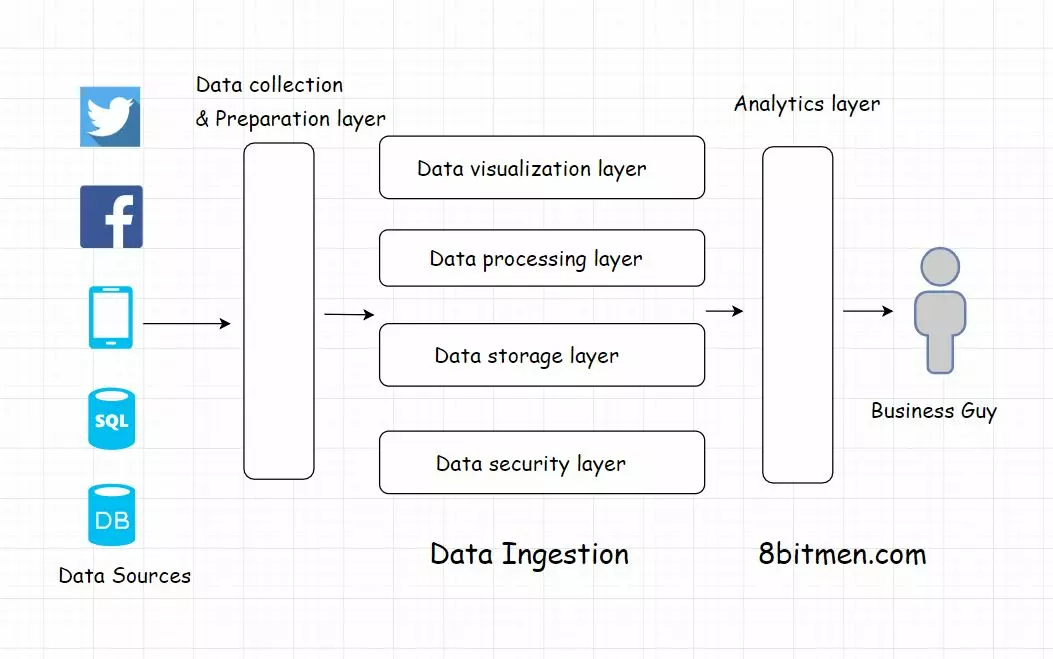
Data ingestion pipeline. Once up and running the data ingestion pipeline will simplify and speed up data aggregation from constant data streams generated by an ever-growing number of data centers. A data ingestion pipeline moves streaming data and batched data from pre-existing databases and data warehouses to a data lake. While traditional pipelines are composed of metals or plastics data pipelines are usually composed of a series of processes software systems and databases.
Business having big data can configure data ingestion pipeline to structure their data. This Azure Data Factory pipeline is used to ingest data for use with Azure Machine Learning. For an HDFS-based data lake tools such as Kafka Hive or Spark are used for data ingestion.
Businesses with big data configure their data ingestion pipelines to structure their data enabling querying using SQL-like language. Supports a variety of data formats storage strategies and scaling options. Data Ingestion Pipeline Data ingestion pipeline moves streaming data and batch data from the existing database and warehouse to a data lake.
Yet our approach to collecting cleaning and adding context to data has. The Data Platform Tribe does still maintain ownership of some basic infrastructure required to integrate the pipeline components store the ingested data make ingested data queryable and simplify. For the strategy its vital to know what you need now and understand where your data requirements are heading.
Once the data has been transformed and loaded into storage it can be used to train your machine learning models in Azure Machine Learning. Just like other data analytics systems ML models only provide value when they have consistent accessible data to rely on. Data ingestion occurs when data moves from one or more sources to a destination where it can be stored and further analyzed.
Thats the purpose of a data ingestion pipeline. What is data ingestion. Data will be stored in secure centralized cloud storage where it can more easily be analyzed.
The data integration is the strategy and the pipeline is the implementation. Design data ingestion flows using a multi-stage wizard-based approach to move your data from any source. Data received by an event hub can be transformed and stored by using any real-time analytics services such as Azure Stream Analytics.
Home Glossary Data Ingestion Pipeline. Data Factory allows you to easily extract transform and load ETL data. Hive and Impala provide a data infrastructure on top of Hadoop commonly referred to as SQL on Hadoop that provide a structure to the data and the ability to query the data using a SQL-like language.
The idea is straightforward. Azure Event Hubs is a big data streaming platform and event ingestion service. Data ingestion is the opening act in the data lifecycle and is just part of the overall data processing system.
Data ingestion is part of any data analytics pipeline including machine learning. Data ingestion pipeline for machine learning. Data ingestion is the transportation of data from assorted sources to a storage medium where it can be accessed used and analyzed by an organization.
By Sam Bott 26 September 2017 - 6 minute read Accuracy and timeliness are two of the vital characteristics we require of the datasets we use for research and ultimately Wintons investment strategies. Every data ingestion requires a data processing pipeline as a backbone. Build automated ingestion applications on the cloud in minutes.
Businesses with big data configure their data ingestion pipelines to structure their data enabling querying using SQL-. Sources may be almost anything including SaaS data in-house apps databases spreadsheets or even information scraped from. A data processing pipeline is fundamentally an Extract-Transform-Load ETL process where we read data.
With an efficient data ingestion pipeline such as Aloomas you can cleanse your data or add timestamps during ingestion with no downtime. How Winton have designed their scalable data-ingestion pipeline. A data ingestion pipeline moves streaming data and batched data from pre-existing databases and data warehouses to a data lake.
The destination is typically a data warehouse data mart database or a document store. So a data ingestion pipeline can reduce the time it takes to get insights from your data analysis and therefore return on your ML investment. With all the new data sources and streams being developed and released hardly anyones data generation storage and throughput is shrinking.
When planning to ingest data into the data lake one of the key considerations is to determine how to organize a data ingestion pipeline and enable consumers to access the data.